문제 : C/C++ 는 컴파일 플랫폼과 타겟 플랫폼(타겟 플랫폼에 의존하기 때문에 컴파일 하는 플랫폼과 다를경우 동작하지 않는다)이 다를경우 프로그램이 동작하지 않는다.
⇒ OS마다 지원하는 시스템 쿼리 투 인터페이스가 다르고 CPU아키텍쳐마다 지원하는 Instruction Set Architecture 가 다르기 때문, 그래서 ByteCode 어쩌고가 다르기 때문에
여기서 시스템 쿼리 투 인터페이스란? : 시스템 쿼리 투 인터페이스(System Query to Interface)는 데이터베이스 관리 시스템과 사용자 또는 다른 프로그램 간의 데이터 교환을 위한 표준화된 언어 및 프로토콜입니다.
(환경,플랫폼 = 운영체제 + CPU아키텍처)
ex) 리눅스 + AMD64 CPU = 플랫폼
리눅스 컴파일 ⇒ 리눅스에 돌려 (이상없음)
리눅스 컴파일 ⇒ 윈도우에서 그 실행파일을 돌려 ⇒ 안됨!
이를 해결하기 위해서 타겟 플랫폼에 맞춰서 컴파일 해야하는데 이것이 크로스 컴파일임
⇒ 리눅스에서 윈도우로 타겟 을 잡고 컴파일 가능
결론 : 원래는 이런식으로 문제를 해결했음
But
JVM은 이문제를 근본적으로 해결함 어떻게? Java 소스 코드가 javac 라는 컴파일러를 거치고 나면 java byte code가 된다 이 java byte code는 JVM이 설치된 플랫폼이라면 어느 OS에서든 실행이 가능하다
⇒ 이 모든 것은 JVM이 플랫폼과 관련된 지저분한 작업들을 대신 해주기 때문에 가능한 일
결국 이것은 디바이스 마다 운영체제나 하드웨어가 다르기 때문에, 자연스럽게 플랫폼에 의존하지 않도록 언어를 설계했다. 그 결과가 Java Btyecode, JVM 이다
컴파일러에도 프론트엔드, 백엔드가 있음 Web에서는 Back엔드는 크게 바뀌지 않음
프론트엔드 - Javac 가 컴파일
백엔드 - JVM 이 컴파일
프론트엔드가 클라이언트의 종류마다 바뀜
그러나 컴파일러는 반대임 컴파일러에서 프론트엔드는 바뀌지 않는다
JVM 내부구조
주목해야할 부분은 Runtime data areas 임
JVM이 Java Byte Code를 실행하는 가상의 기계인데 그때 여러가지 종류의 메모리 공간이 필요한데 그때 사용되는 것이 Runtime data area 임
Runtime data area는 method,heap,Java stacks, pc registers, native method stacks 이렇게 5개의 공간으로 나뉨
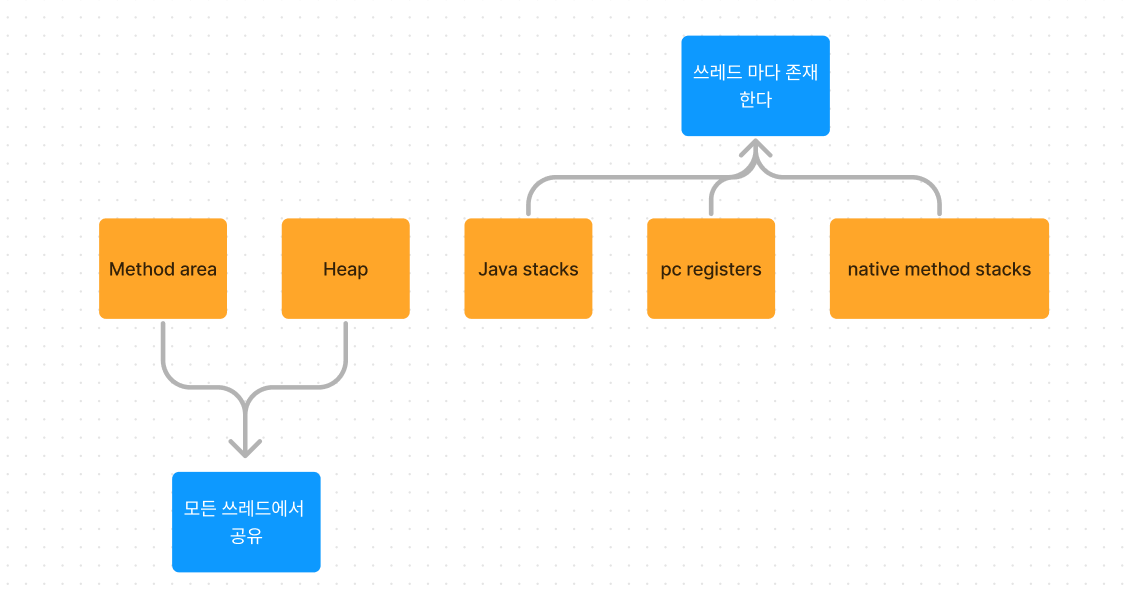
- Method : method area는 클래스 로더가 클래스 파일을 읽어오면, 클래스 정보를 파싱해서 Method Area에 저장한다.(변수, 메서드가 어떤것이 있는가? 정적변수, 바이트코드는 어떤가? 이런것들을 저장)
- Heap : Heap은 프로그램을 실행하면서 생성한 모든 객체의 인스턴스를 저장하는 곳
- pc registers : 각 스레드는 항상 어떤 메서드를 실행하고 있고 pc(program counter)는 그 메서드 안에서 몇번째 ByteCode를 실행하고있는지 알려준다
- java stacks : stack은 쓰레드별로 한개씩만 존재한다. 스택 프레임은 메서드가 호출될 때마다 생성된다. 메서드 실행이 끝나면 스택 프레임은 pop되어 스택에서 제거된다.
- native method stacks : Java Btyecode가 아닌 다른 언어로 작성된 메서드를 의미한다.
(객체 지향 프로그래밍에서 클래스와 인스턴스는 설계도와 제품의 관계로 비유할 수 있다.)
(객체지향프로그래밍에서의 인스턴스란?
인스턴스는 클래스의 구체적인 구현입니다. 예를 들면 Dog myDog = new Dog(매개변수타입) 이 경우 인스턴스는 메모리에 할당된 객체를 의미입니다.
new는 객체를 메모리에 할당하고 생성자를 호출합니다.)
java stacks, pc registers, native method stacks 이 세가지는 쓰레드마다 존재한다
여기서 각 쓰레드는 어떤 메서드를 항상 실행하고있다
Java는 다양한 디바이스에서 균일하게 동작할 수 있음을 보장하고자 했습니다. 각 디바이스마다 레지스터의 수와 특성이 다를 수 있기 때문에, 레지스터 기반의 구현을 사용할 경우 특정 하드웨어에 종속적이게 됩니다. 예를 들어, 레지스터 1, 2, 3을 사용하는 순간, 해당 레지스터 세 개가 필요하게 됩니다.
하지만 스택을 사용하게 되면, 계산 과정은 귀찮고 복잡하게 되더라도 하드웨어 스펙에 최소한으로 관여하게 됩니다. 따라서 추상화를 위해 스택을 사용하는 것이 바람직합니다. 또한 스택 기반의 코드는 더 컴팩트하게 작성될 수 있어, 네트워크로 전송할 때도 이득이 됩니다.
'Back-End' 카테고리의 다른 글
| [Back-End] JPA 개념정리 (0) | 2024.06.07 |
|---|---|
| [JPA] TEST코드 수정 (0) | 2024.06.07 |
| 감사 추적기능 (0) | 2024.06.05 |
| HTTP 상태 코드 (하나씩 쓰면서 공부하는 중) (0) | 2024.06.05 |
